Do Massive Site Scans Actually Improve Data Quality?
Introduction
Conversations about tracking quality have long been dominated by the idea that automated massive scans (aka tag audits) inevitably improve the overall quality of the data you collect.
The thinking is that periodically scanning all the URLs of a given website will flag issues occurring on specific pages, allowing you to fix the observed defects in a timely fashion. Tag audit vendors have made large-scale scans the centerpiece of their offerings, resulting in products that reinforce the notion that scanning many pages is a prerequisite for improved data quality.
Such scans often produce tag audit scores calculated through the spidering of thousands of URLs and evaluating them against various assessment criteria (missing tags, multiple tags, tag compliance rules, etc). This gives the illusion of tangible data quality measurements ("If my tag audit score is going up, data quality must be improving!") coupled with the false sense of comfort and accomplishment that comes from knowing that an audit covered (hundreds of) thousands of URLs.
This notion of massive scans as the main tool for success is at complete odds with the reality of practical tagging validation. The most crucial and time-consuming part of any reasonably sophisticated tagging implementation has always been the conversion events and the various meta-data they carry as they capture complex user interactions (cart check-outs, registration forms, etc). Site scans are not smart enough to reproduce any real user interactions, and they make up for it by telling you pretty much everything else except what you really want to know: are my KPIs tagged correctly?
In this blog post we’ll discuss the most pernicious aspects of the massive site scan myth and propose the alternative notion that any robust automated tag validation strategy should in fact begin with validation of the event tags across key user flows.
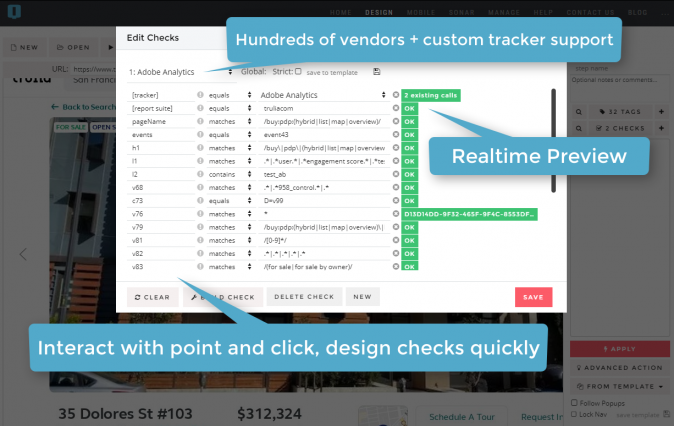
Understanding tag audits
All automated scans involve a crawler cycling through your site's pages. As it loads each URL, the crawler records as much data as it possibly can from the page and stores it for review. This includes links to other site pages to load next.
The tools used to scan page-level tags come from the world of generic quality assurance (QA). Behind the scenes, a script framework such as Selenium is used to control one or more "headless" browsers to do the work. Tagging QA solutions piggyback on the native ability of these harnessed browsers to intercept network requests and attempt to identify tracking beacons that belong to known MarTech vendors (Adobe Analytics, Google Analytics, Facebook, etc.) In addition, they apply rules (some baked into the system, some supplied by the end user) to evaluate the contents of such tracking requests vs. the expectations of the analyst.
The findings are typically recorded and presented in a tabular format, along with some gauges purporting to award an "audit score" and measure the current tagging against a "100% optimal" ideal.
Can you already tell what’s problematic with this approach?
What about the KPI?
Spiders work by following links. However, key user interactions are never just a random set of loaded pages.
One of the simplest examples, a user creating a new account on a website, involves not only landing on the account creation page, but also providing a username, a password, and possibly some additional information before clicking on the account create button. The next step in the registration flow takes the new user to a newly authenticated state that no bot can even reach without knowing how to complete a valid user registration form. Along the way, some of the most crucial conversion tags will fire (or not!).
For an automated test to be able to trigger and validate the user interactions driving the "New Account Registrations" metric in analytics reports and dashboards, the headless browser would need to fill out all the fields with valid input before clicking on the right button to submit a "Create Account" request. Scans of the sort employed by tag audits may be able to sniff out the page URL of the account create form, but don't know how to interact with the form the way a user would.
As a result, while covering many pages (going wide), tag scans are incredibly shallow. All meaningful KPI tracking occurs too deep for them to see. The quantity of information page-level scans produce is not a substitute for quality.
My site has a million URLs. How can I check them all without massive scans?
Your site may have a million unique URLs, or even a billion, but most likely it only has a few dozen unique templates / page types at most. Maybe a few hundred, if you are the word's largest website.
For instance, your product catalog may contain thousands of individual SKUs, and each product gets its own URL, but under the hood all product detail pages are constructed dynamically using the same set of template elements. A tag audit of a hundred thousand unique product URLs will return the same results as a tag audit of a representative sample. Scanning more URLs for the sake of scanning URLs does not buy you additional data quality. It can, however, cost you. Real issues may lay buried in a sea of data produced by over-scanning, or even more likely, may lurk just an inch deeper than that massive scan could go.
Scans are costly in the literal sense as well. For one, they run up the bill quickly. Often times vendor discussions around pricing begin with the question, "How many unique URLs does your site have?" This question is a lead-in to a flawed tag validation strategy based on pointless crawling of the same templates for the sake of hitting some URL quota deemed adequate for the magical improvement of data quality.
My site only has one URL. What can site scans do for me?
Single Page Applications expose the futility of tag scans in the most categorical way. Your web app may only have a handful of unique URLs and a tag audit based on scanning your SPA website for distinct pages will fall woefully short of delivering any value whatsoever. Your SPA may have links and buttons with URL's, sure, but most spiders do not actually click on links. They harvest them and attempt to access them directly. This is only incidentally possible inside an SPA, and departs more or less completely from how an actual user experiences the site.
SPAs force people to think outside the paradigm of vendor-imposed page-level scans and audit scores. Tracking user interactions and the tags they fire in web applications requires a thoughtful approach to QA automation that will in fact yield the same benefits for any type of website. They force you to think outside the box of "page URLs" and recognize the simple fact that a sensible QA automation strategy must begin with flow-based validation technology.
Bring the noise!
Going back to the copious amount of data that shallow site-wide scans produce in a poor attempt to substitute quantity for quality, some vendors go truly nuts.
Often, tag audits have dozens of categories: page load times, SEO metrics, status codes, cookie inventories, tag script sizes and load speeds, tag vendor breakdowns and hierarchies of tags, tag firing order, duplicate and multiple page-level calls from the same vendor, potentially missing tags (from auto-compare with other pages). And at the bottom level, if you can even dig that deep, individual tracking parameter checks specified by the analyst.
The effect they're going for is a sense of completeness. The actual result is noise.
In the vast majority of cases, even detailed inspections of such findings yield zero value. Upon reflection, one realizes that there are specialized (and often free) tools that are better suited to the analysis in question and produce a much more precise diagnosis of the underlying issues (e. g. Google's PageSpeed Insights aka Lighthouse).
Most of the generic checks applied to the avalanche of scan data are, quite frankly, inconsequential. One example is the "multiple tags" alert. Having multiple tags from the same vendor on a given page is often completely intentional. Chasing down hundreds of false leads can be both exhausting and distracting. Another example are the so-called "slow" or "under-performing" tag warnings. Most of the time these are red herrings or stem from tough compromises well-known to site developers.
The information overload produced by typical tag scans can quickly become part of the problem, not part of the solution.
Reports frequently include a lot of things you already know, a lot of red ink that turns out to be false alarms, and a few nuggets buried deep down that may be useful to follow up on one time. Fine-tuning the scans is usually possible at the level of "custom rules" but doesn't address the core issue of too much information of the wrong / inapplicable sort.
One of our big goals here at QA2L is to rethink scanning in a way that surfaces actionable alerts. It's a challenge we take seriously.
Does checking from different geolocations make any sense?
One of the touted features of massive tag scans is the ability to perform audits from different geolocations. But this ability is not unique to site scans. Any cloud-based QA automation strategy can be distributed around the world. The question is, is it worth the extra cost and effort? In the vast majority of use cases the answer is, not at all.
The premise that tags may somehow perform differently for requests originating from IP's in different geographical zones is largely a myth. From a functional standpoint, tags will fire the same exact way regardless of where the requests originate from.
A decade ago, with locally-built data collection systems, one may have argued that while functionality-wise tags behave the same way, there might be performance delays with tracking requests being routed through multiple remote geos. With the advance of distributed cloud computing however, this is hardly a concern with many vendors offering data collection that is dynamically optimized to serve pixels from a regional data center.
There absolutely are sites that behave differently based on geolocation, and that may include variance in tracking as well. But the key point here is, these differences in site behavior can always be emulated. If you are QA'ing analytics for a global website, simply ask your developers how they code for different regions (spoiler: they don't travel around the world for every site update). That is how you will want to automate the tagging QA process for those other regions as well.
How about checking tags using different desktop browsers?
The situation is quite similar to that with geos, including the part where this is not really a capability unique to site scans, but rather just another forced selling point.
Similarly to geos, testing with different desktop browsers rarely (never?) uncovers tagging issues that are not the consequence of the site itself misbehaving or behaving differently. More importantly, like geos, switching between different desktop browsers can be emulated sufficiently well to make the website think that you are on a certain browser when you are actually not. This is enough for tag QA purposes.
The added cost associated with running the same tests natively on different browsers is just that, an added cost.
In other words, leave the native browser testing to developers and functional QA specialists. Focus on making sure your essential tags fire as expected.
If you are QA'ing a responsive website, or your site has a very different mobile version, it is much more important to focus on desktop vs. mobile than on IE vs. Chrome. Again, the right question to ask here is not: "Can you auto-scan our mobile site as well?" You should instead start from the key experiences your mobile app enables, some of which may be unique.
The overhead
In general, running the same set of tagging tests from different locales or with different browsers is a diminishing returns proposition. Multiplied by indiscriminate scanning, the overhead can become excruciating.
At some point, even site performance may be impacted by the amount of automated URL scanning going on in the name of data quality.
At the end of the day, your limited resources are much better spent at making your QA automation solution smarter and better at catching the issues that cause you the most pain.
GDPR and privacy compliance laws
Scanning all your pages is necessary in order to ensure privacy regulations are met…, or at least that's how the elevator pitch goes.
It is true that going through a list of URLs and identifying vendors that are not expressly approved at the top level can be achieved through indiscriminate scanning. But that's just a baby step. In order to truly meet privacy regulations, websites must also take into account:
- the site flows through which users communicate their privacy preferences (e. g. OneTrust opt-outs).
- the site flows that may exhibit different tracking behavior based on user privacy preferences.
- the site flows where the exchange of PII (Personally Identifiable Information) actually takes place (email subscriptions, orders, account sign up pages).
In order to automate a thorough set of GDPR compliance checks, you need intelligent tag validation across key workflows.
Conclusion
When implemented reasonably (as we've done here at QA2L) site scans can be a valuable weapon in your data validation arsenal. They are, however, fundamentally limited in that they cannot reach the really important tags set throughout key user flows.
Tag scans are even more helpless in the context of single page applications, and often produce more noise than they do actionable alerts.
In the context of privacy regulations, violations to regional privacy laws and inadvertent collection of PII are more likely than not to remain undetected by scans, as they generally don't have the smarts to perform the set of user interactions that trigger privacy violations.
A comprehensive automated tag QA strategy, much like any analytics implementation, should begin with identifying the KPIs, their attributes, and the key user journeys where these data points are collected. The only way to efficiently improve data quality through QA automation is to use flow-based validation, a technology capable of faithfully executing any series of user interactions.
Also Read
Tags: Data Quality Trends